SpeAKN: Speak for ALS with Korean NLP

Project Overview
SpeAKN (Speak for ALS with Korean NLP) is an innovative AI-powered communication system designed specifically for ALS patients who have lost their ability to speak. The system combines eye-tracking technology with advanced Korean natural language processing to provide contextually appropriate response suggestions, enabling meaningful communication for patients with progressive motor function decline.

Problem Statement
ALS (Amyotrophic Lateral Sclerosis) is a neurodegenerative disease in which motor nerve cells in the brain and spinal cord progressively deteriorate. Over time, ALS patients lose their ability to communicate using natural language, with 80-95% of patients requiring alternative communication methods known as AAC (Augmentative and Alternative Communication).
Existing solutions like "Look to Speak" require users to make numerous selections before reaching their intended response, and users cannot pre-input their desired responses. Our AI-TRACKING system addresses these limitations by combining eye-tracking technology with artificial intelligence to provide contextually relevant response options.
Technical Architecture
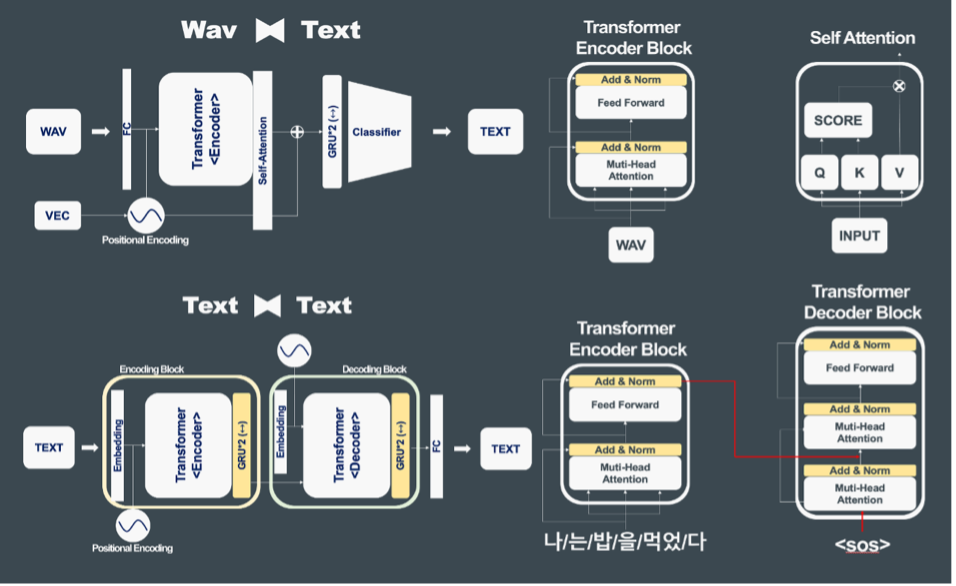
System Pipeline
The SpeAKN system operates through a two-stage AI pipeline:
- Speech-to-Text (Wav2Text): Converts incoming voice questions to text using advanced speech recognition
- Context-Aware Response Generation (Text2Text): Analyzes the textual context and generates appropriate response options
- Eye-Tracking Selection: Patients select their intended response using eye movements
Data and Training
Dataset
This project utilized the National Institute of Korean Language's datasets:
- Everyday Conversation Speech Corpus 2020: 870,162 audio files and 2,231 corresponding sentence data points
- Everyday Conversation Corpus 2020: 2,232 sentence data points
- Total data: ~500 hours of conversation data from 2,739 participants
- Audio format: 16kHz PCM format
- Text format: UTF-8 JSON encoding
Model Optimization
We experimentally tested various optimization approaches:
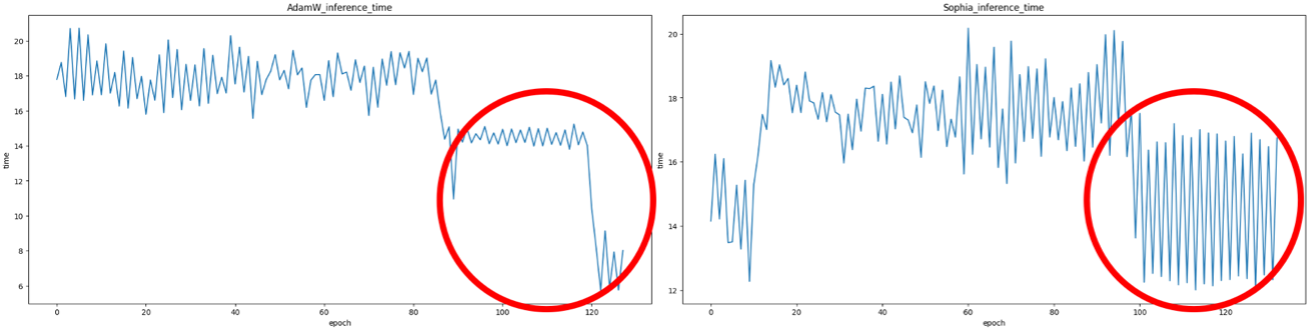
The AdamW Optimizer demonstrated superior performance with faster learning progression and better stabilization during training compared to the Sophia Optimizer.
Architecture Innovations
Our SpeAKN model employs several key innovations:
- GRU Layers: Successfully overcome vanishing gradient problems, particularly effective for Korean language processing
- Transformer Encoders: For robust feature extraction from speech and text
- Self-Attention Mechanisms: To capture long-range dependencies in Korean conversations
Audio Processing Optimization
To handle varying audio lengths efficiently, we analyzed the distribution of audio data lengths:
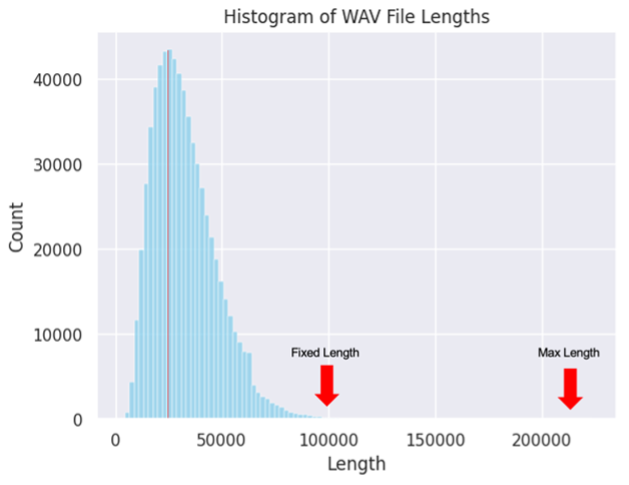
We set the standardized audio length to 100,000 samples to balance computational efficiency with data preservation, avoiding the curse of dimensionality while maintaining essential information.
Results and Performance
Initial Performance Metrics
| Model Component | Train MSE | Validation MSE | Input Type | Output Quality |
|---|---|---|---|---|
| Speech2Text | 10.039 | 12.569 | Voice/Question | Moderate accuracy |
| Text2Text | 11.234 | 13.788 | Text/Answer | Requires improvement |
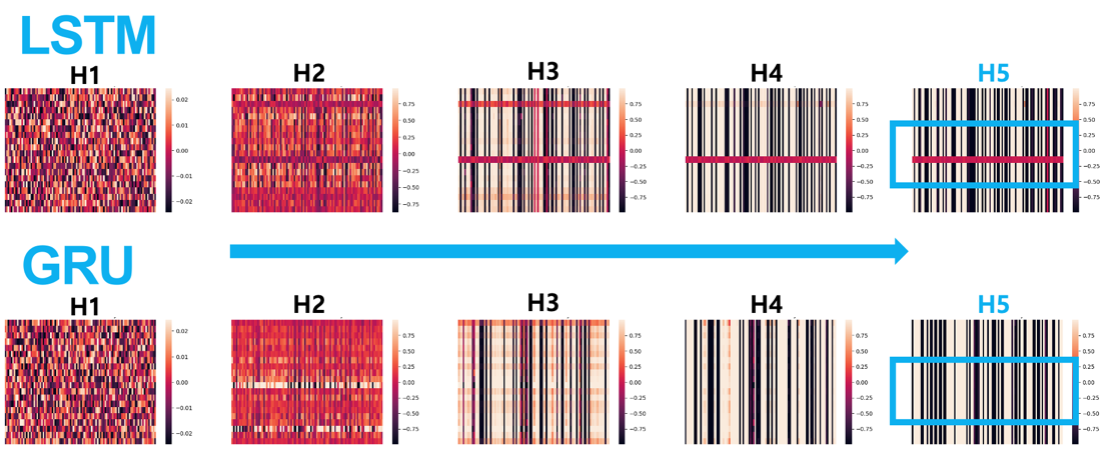
Attention Visualization
To verify model learning effectiveness, we visualized attention patterns:

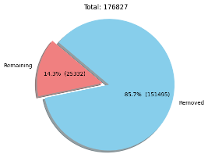
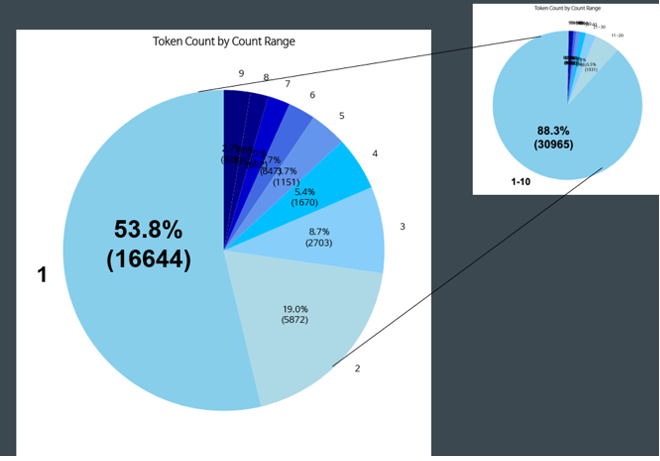
Data Quality Analysis
Our analysis revealed important insights about the training data:
Korean Language Challenges
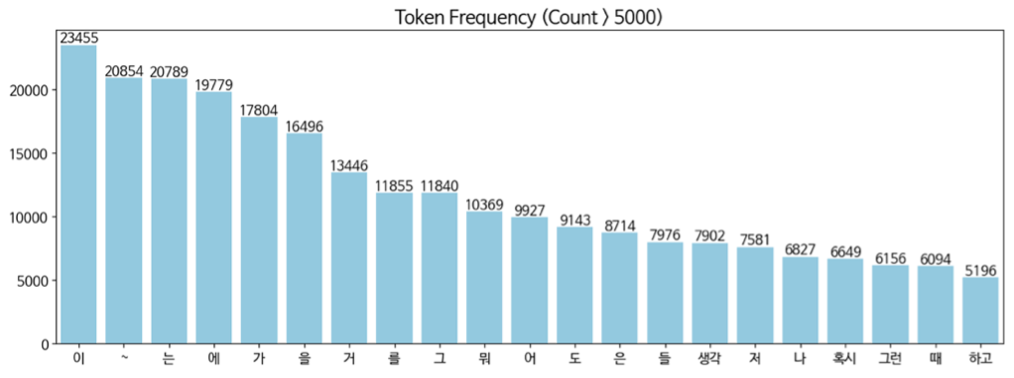
We identified specific challenges related to Korean language processing:
Eye-Tracking Implementation
The final system integrates eye-tracking technology for user interaction. When a question like "아픈 곳은 없어요?" (Do you have any pain?) is processed, the system generates contextually appropriate response options that patients can select through eye movements.

Technical Implementation Details
Key Features
- Real-time Speech Processing: Immediate conversion of caregiver questions to text
- Context-Aware NLP: Korean language-specific processing for accurate response generation
- Adaptive Interface: Eye-tracking based selection system requiring minimal motor function
- Personalization: Learning from user interaction patterns over time
Technical Stack
- Speech Recognition: Google SpeechRecognition API
- Language Model: Kakao KoGPT for Korean text generation
- Deep Learning: Custom transformer and GRU architectures
- Eye-Tracking: Computer vision-based gaze detection
Team Collaboration
Development Team
- June Lee — Project Lead, NLP Architecture
- Ohjoon Kwon — Speech Processing
- Youngjin Jeong — Model Optimization
Research Team
- Chaeyeon Kim — Data Analysis
- Jeongmin Lee — Eye-Tracking Implementation
- Faculty Advisors — Clinical Guidance
Impact and Future Directions
Clinical Significance
SpeAKN represents a significant advancement in assistive technology for ALS patients by:
- Reducing communication time and cognitive load
- Providing contextually relevant response options
- Adapting to progressive motor function decline
- Supporting Korean language-specific communication patterns
Future Enhancements
- Integration with additional AAC modalities
- Advanced personalization through continuous learning
- Expansion to other neurodegenerative conditions
- Real-time emotion recognition and response adaptation
- Multi-language support for diverse patient populations
Open Source Contribution
The eye-tracking implementation is available as an open-source project: https://github.com/junhyk-lee/Look_to_Speak
Research Publications
This work contributes to the growing body of research in assistive technology and demonstrates the potential of AI-powered solutions for improving quality of life for patients with neurodegenerative diseases.